
- Building With Ruby on Rails
- Technical Metrics
- Getting Started With Multiple Databases
- From SQL Joins to Multiple SELECTs
- New Database Configuration
- Post-split: Subquery Expressions
- Post-split: EXISTS Clauses
- Post-split: Aggregating And Grouping Multiple Tables
- Post-split: Merging Scopes
- Post-split: References Method
- Other Associations: has_and_belongs_to_many
- Scaling Inserts and Updates
- Scaling Reads With Batching
- Scaling Reads With Paginated Queries
- Counter Cache Maintenance for Frequently Updated Counters
- Random Values and Sampling
- Using Memory Key Value Cache Stores
- Managing Schema Changes with Multiple Databases
- Wrap Up
Ruby on Rails has helped make it possible to scale out the database layer, meeting the demands of millions of Aura Frames customers enjoying their digital photo frames.
In late 2025, the team added additional primary databases to expand capacity for peak write and read load ahead of Christmas Day, the busiest day of the year for the company. Rails manages queries and schema changes for each primary database within the same codebase, and now with the additional capacity of many primary databases.
With 8 primary databases in total, each server instance can be vertically scaled ahead of peak load. When load returns to normal levels, instances are scaled down for cost savings.
The team leveraged native support for Multiple Databases and the disable_joins: true feature in Active Record, the ORM for Ruby on Rails. The disable_joins feature replaces SQL joins, issuing multiple SELECT statements to combine data in the application from different databases.
This post looks back at the technical details of that plan, as well as a variety of additional data layer scaling tactics, that culminated in a successful Christmas 2025 season, with peak U.S. and Canadian Apple App Store and Google Play Store rankings of #1.
Building With Ruby on Rails
The Aura Frames platform has been built with Ruby on Rails since the beginning (more than 10 years ago!). Christmas 2025 was the busiest day of the year for the company and technical platform, serving a peak of 41 million API requests per hour (~11.4K requests per second), and processing a peak of 11.8 million background jobs per hour (~3300 jobs/second). On the database side, the sum of DB peak transactions per second (TPS) was 226K.
For an introduction to the Aura Frames company and products, and a deeper dive on the Postgres side of things, please check out Part 1 of this series.
Brief Recap from Part 1: Besides Ruby on Rails, Aura Frames uses PostgreSQL and AWS as key technologies.
Due to not being easily scalable horizontally for write operations, the database layer of PostgreSQL and Active Record often became a bottleneck. The team relied on vertically scaling the single primary server instance through Christmas of 2024.
The largest instance available for RDS at the time was the 48x family (192 vCPU, 1.5 TB RAM). Even with that jumbo-sized instance, the platform had reliability issues at peak load on Christmas 2024, driving a need to re-design for reliability improvements before Christmas 2025.
To handle greater levels of peak traffic reliably, the team decided to introduce application-level sharding using multiple primary databases. Several alternative approaches were considered. One goal was to leverage the existing code as much as possible, with minimal changes, and control the sharding distribution from the application level.
Another choice was whether to do traditional sharding at the row level, which distributes rows across multiple instances with databases having the same schema.
Fortunately Ruby on Rails was enhanced through more than 15 years of development, to support the needs of mature, scaled-up platforms with billions of rows and terabytes of data.
Before getting into the solution details, let’s look at some technical metrics from Christmas Day 2025 to help set context.
Technical Metrics
On Christmas Day, the Aura Frames platform sees a 4-5x increase in load. Below are some HTTP and background jobs oriented metrics that Rails developers might find interesting.
| Metric | Peak Value |
|---|---|
| HTTP Requests (1pm CT) at Load Balancer | 41 million requests/hour |
| Average Response Time (10am to 9pm CT) | 650 milliseconds |
| Cloudfront Global Requests | 33,675,000 requests/hour |
| Image Processing EC2 Instances Count | 2990 |
| API EC2 Instances Count | 1849 |
| Background Job Processing Rate | 11.8 million jobs/hour (~3300 jobs/second) |
An exciting development for the team was seeing the free iOS and Android Aura Frames app rise in ranking throughout the day.
Late on Christmas Day, the app reached a peak rank of #1 among all free apps in the U.S. and Canadian App Stores, beating apps from big companies like OpenAI (ChatGPT) and Meta (Meta AI)!
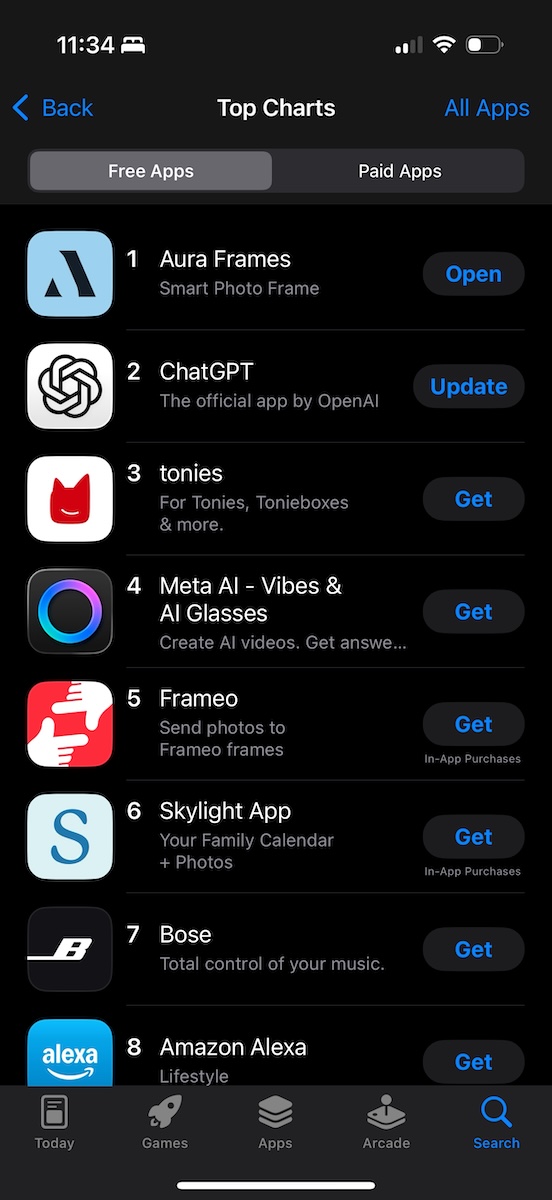
Screenshot showing the Aura Frames app at the #1 rank in the U.S. Apple App Store
Although there is a lot of interesting history from how the Aura Frames Ruby on Rails codebase evolved over a decade, in this post we’ll focus on changes made from mid-2025 to prepare for the surge of traffic on Christmas Day, as well as some general data layer scaling tactics.
Getting Started With Multiple Databases
From earlier, you learned that the Aura Frames platform was expanded from a single primary application DB to a total of 8.
To do that, heavy refactoring was performed to Active Record query layer code.
Queries for tables must not span a database boundary, and given some of the big tables were being moved to a new database, queries would break.
The development environment uses a Docker Postgres container. To keep things simple locally, all 8 databases run within the single container, but are spread out as separate Postgres databases. This meant that queries still “broke” (helpfully) when they spanned a database boundary, making them easy to find through unit tests and manual testing.
The gist of the changes were pretty straightforward: find breaking queries, unravel joins or other incompatible SQL, and change connections for those queries to access the correct database. Their query results were then passed around in Ruby as input to queries in other databases.
With hundreds of failing tests to sift through, the refactoring work took a long time as test failures were addressed one by one, but progress was easy to measure.
Eventually, weeks later, all tests were passing! The nice property about this design was the same query changes without SQL joins could be performed on the existing main DB, meaning the query changes were backwards compatible and could be rolled out on the single primary DB.
Some of the main changes were evaluating all Active Record relationships (has_many, belongs_to, etc.) and any subquery expressions or other incompatible code, and using disable_joins: true, removing subquery expressions and table references that spanned the boundary.
From SQL Joins to Multiple SELECTs
The key parts of Ruby on Rails and Active Record that made this possible were Multiple Databases launched in 6.0, and the disable_joins feature for has_many :through and has_one :through relationships to query across databases launched in Rails 7.0 (2021).
Both of these were possible with custom code or third party library code (Ruby gems) prior to those releases, but having native support in Rails was a differentiator. Native support meant more real world use, bug fixes, improved documentation, and a longer term commitment to support.
Having disable_joins as a consistent pattern also helped with comprehension by the team, enabling “learn how it works once, then re-use it all over the codebase.”
Due to the increase in SELECT queries (and loss of join efficiency), the team had concerns about additional read query volume. Fortunately the team had a load testing tool in place and was able to verify through load testing that the additional read queries performed would not be a problem. With that said, over time we have replaced certain usages of disable_joins associations code with more targeted queries based on slow query logs or query cancellations. These queries are index supported, select minimal fields, and narrow ranges of rows by using batching.
Here’s a simple example using Author and Post models illustrating how disable_joins: true works:
- Author (table_name:
authors) - Post (table_name:
posts) - AuthorPost (table_name:
author_posts)
Author model has an existing association defined as: has_many :posts, through: :author_posts.
To change this association, the disable_joins: true option is added like this:
class Author < ApplicationRecord
has_many :posts, through: :author_posts, disable_joins: true
end
What’s happening in SQL? Previously to get an Author’s posts, we’d query the author_posts table and join to the posts table on the author’s id.
Instead of that, there will now be two SELECT queries. One queries author_posts by author_id (an important foreign key column to index) to get post id values. Then a second query to the posts table by id (which uses the primary key index) gets the rows from the second table.
select * from author_posts where author_id = '<some id>';
select * from posts where id IN (?);
Active Record handles the query change and presents the objects and collections in the same way to the developer.
Besides the query changes, what else needed to change?
New Database Configuration
Although we rolled out the query changes on the single primary DB architecture initially, that was intended to be temporary to further validate the changes without needing the new DBs in place.
The main plan was to use separate DB server instances, relocating the largest, busiest tables to their own instances in order to add more capacity and distribute the load.
For that we’d need to provision all the new DBs and connect to them from Rails. The first thing we needed was new YML config entries (config/database.yml) for each of them. The Multiple Databases Documentation uses “animals” and my_animals_db as the second primary database, so we’ll use that too for examples here.
This configuration is where we’ll store the Postgres connection string details and other application config like whether migrations are used, the schema dump path, etc.
Second, Active Record classes that previously inherited (OOP style) from ApplicationRecord < ActiveRecord::Base would get a new parent class.
The new parent class would introduce the new DB config for my_animals_db and have the concept of “writing” and “reading” roles, shown below.
The new class is AnimalsRecord, which is a child class that inherits from ApplicationRecord. Extending this new parent class becomes the “interface” for any additional Active Record classes that wish to read or write to this new DB.
Examples from Rails’ Documentation:
class AnimalsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: {
writing: :animals,
reading: :animals_replica
}
end
Models/tables inherit from AnimalsRecord to work with that database. For example a Dog class:
class Dog < AnimalsRecord
# Talks automatically to the animals database.
end
Eventually all new DBs and infra (PgBouncer, config vars) were set up, and could be switched over to. In the Rails app, the new DBs were named generically as they didn’t really correspond to a particular grouping of activity like a service, we just wanted a bunch of DBs with unique names.
The names of the DBs were part of the parent model, now the parent of the original model. Since the original model doesn’t change apart from having a new parent class, the new DB details are nicely encapsulated.
disable_joins for has_many :through relationships ended up covering a lot of what was needed for query database separation, however there were other issues encountered on the way.
What were they?
Post-split: Subquery Expressions
Multiple tables exist in subquery expressions (aka “subqueries”), and these tables need to be in the same database for the statement to be valid.
When we found those, they needed to be restructured so that the DBs containing the table could be queried.
Post-split: EXISTS Clauses
Post-split, the SQL below doesn’t work when users and posts (example models) aren’t in the same DB.
SELECT users.*
FROM users
WHERE EXISTS (
SELECT 1 FROM posts WHERE posts.user_id = users.id
)
Post-split: Aggregating And Grouping Multiple Tables
Post-split, there can be SQL fragments like this lurking, and this code needs to be changed when these tables are moved to separate databases.
SQL fragments are wrapped in Arel.sql('').
Users.select("users.*, COUNT(posts.id) AS posts_count")
Post-split: Merging Scopes
If the tables for User and Post aren’t in the same database, we can’t merge a scope like this:
User.merge(Post.recent)
Post-split: References Method
references API Documentation which adds a SQL join, is used in conjunction with includes() to specify a table. However, this won’t work if the table is no longer in the same database.
Other Associations: has_and_belongs_to_many
We did have a handful of has_and_belongs_to_many (HABTM) relationships (API Documentation). With these there is still a join table, but there is no Active Record model for it. The tables are also slim, no primary key or timestamp columns.
For HABTM relationships that would span a DB boundary, we decided to keep the table definitions as is, but introduce a model class and convert the code-level relationship from HABTM to has_many :through (HMT) so that we could use disable_joins: true.
Not all HABTM relationships were changed. When the HABTM relationship tables stayed in the same DB, we left those untouched.
Let’s shift gears into some general additional data layer scaling tactics.
Scaling Inserts and Updates
With Multiple Databases and disable_joins: true covered, what other database scalability tactics are used?
Rails supports bulk inserts and upserts (either an insert or an update), however the helper method for mass-inserting data didn’t support what we needed. A limitation was that the ON CONFLICT clause couldn’t be customized for insert_all() (API Documentation), which we needed.
For example attempting an INSERT and specifying the DO NOTHING option for handling unique constraint violations.
However, upsert_all() did get support for an :on_duplicate option.
Aura Frames has custom code for mass insert with direct control over the ON CONFLICT clause. Being able to batch inserts like this is a critical part of write scalability, consolidating the overhead of a batch of row insertions (e.g. 1000) into a single commit.
Scaling Reads With Batching
Rails supports batched read queries with a few Active Record methods: find_each(), in_batches(), and find_in_batches().
Aura Frames has custom code for batched finding, specifying an arbitrary column on the table and a sorting direction.
Rails 6.1 did add support for find_in_batches() (API Documentation to control ordering, but only the primary key column was supported for ordering in ascending or descending order. We needed to order on arbitrary columns.
Chedli Bourguiba pointed out that Rails 8 added a :cursor option to support cursor pagination on a non-primary key column. See more at: JetThoughts - Ruby on Rails 8: How to Batch with Custom Columns. I will be evaluating this in the future.
Reading a batch of rows using keyset pagination is a critical tactic for stable query execution times with varying result set sizes.
Scaling Reads With Paginated Queries
Aura Frames has custom code to perform keyset pagination, and generally does not use LIMIT and OFFSET style pagination built-in to Active Record. LIMIT and OFFSET pagination works for smaller amounts of data, but doesn’t scale well for deep pagination levels or when working with tables with billions of rows.
Keyset pagination with a high cardinality indexed column works well for fetching batches at a time, even when querying multi-billion row tables given they have good supporting indexes. The trick is to index a high cardinality column like a timestamp column, then filter on that with a WHERE clause and use LIMIT for a batch of rows. Note that timestamps can be duplicated, so you may need an additional column in that case.
An example fetch might be from a value with a >= or < operator and a LIMIT of 1000 as a batch size. The last accessed value then becomes the cursor position to start from.
This is an incredibly useful pattern and commonly used for API requests and other spots. To my knowledge Active Record doesn’t have a generic keyset style pagination helper.
Counter Cache Maintenance for Frequently Updated Counters
Rails supports counter_cache columns (Blog post) as a running counter, which is kept updated at write time.
Caveats are row churn and possible lock contention. Even updates of a single column create a new immutable row version behind the scenes. This adds dead row versions and more work for Vacuum, but this trade-off may be worth it.
Aura Frames does something similar but keeps counter cache columns in a separate but related table (plus counters in Memcached, see below). This reduces contention and places the churn more on a separate utility table.
Random Values and Sampling
Ordering by RANDOM() is slow. To avoid that, the Aura codebase uses TABLESAMPLE in Postgres (a contrib module which means no extensions are needed to install). A tablesample can be specified in a FROM clause (Postgres Documentation).
As a quick example from Rideshare using the Trip model (trips table) as SQL:
Trip.connection.select_all("SELECT * FROM trips TABLESAMPLE SYSTEM (10)").to_a
Or as more conventional Active Record, requesting 5% of rows (1000 rows in this table):
Trip.from("trips TABLESAMPLE SYSTEM (5)").count
Trip.from("trips TABLESAMPLE BERNOULLI (5)").count
The sampling_method options (built-in) above were SYSTEM and BERNOULLI. With 1000 rows in my local table, I should get about 50 rows by specifying 5%, but if you run this you’ll notice it’s only approximate. System is faster, but neither are fully accurate.
To get a precise amount of rows, enable the tsm_system_rows extension (Postgres Documentation) and specify a row count like this:
Trip.from("trips TABLESAMPLE SYSTEM_ROWS(50)").count
Trip Count (11.9ms) SELECT COUNT(*) FROM trips TABLESAMPLE SYSTEM_ROWS(50)
=> 50
You’ll notice above we got exactly 50 rows.
This tactic is used in various scripts and utilities where samples are needed from tables with millions of rows.
Using Memory Key Value Cache Stores
Aura Frames makes use of the Active Support Cache Store via Memcached with HAProxy performing connection management.
Keeping certain values in Memcached is a key part of the scaling strategy, values like per-user counters, per-feature rate limiting, or cached environment variable values with TTLs.
Managing Schema Changes with Multiple Databases
With the 7 new DBs and configs in config/database.yml, we wanted to continue managing DDL changes via Rails Migrations like normal.
Fortunately this is supported. Each DB has its own schema.rb, a Ruby representation of the schema definition, a directory for migration files, and a place for config options.
Since each “new” database was not actually new, but based on an existing table definition, we started a new “first” migration for it using the existing table definition dumped via pg_dump.
This migration version was written to be idempotent meaning the table was added only when it didn’t exist. Initially the table would not exist in dev, test, and staging, but based on how we planned to migrate the tables in production, the table would exist there.
Brief recap from Part 1: The plan was to use physical replication from the original primary instance to create a read only replica, then promote it to become a writer database. The replication was used as the means of moving all of the row data. This approach proved very reliable, but it did mean we had the former table copy on the original DB to clean up later, plus a ton of unneeded tables on all the new DBs to clean up (more on that in the other post).
Imagine the new migration version was 1234567890. Once switched over, we’d TRUNCATE its schema_migrations table, then manually insert the new migration version into schema_migrations to keep the state consistent.
insert into schema_migrations (version) values ('1234567890');
That was repeated for each new DB. Once that was done, schema management via migrations worked like normal, each seeded with their initial create table DDL as of that moment in time.
Migrations could be generated with their own directory for files, applied with rails db:migrate and schema.rb kept updated.
Some example commands:
rails g migration --database new_db
rails db:migrate --database my_animals_db
# or rails db:migrate for all databases
rails db:schema:cache:dump
Wrap Up
Ruby on Rails has been a critical technology for Aura Frames to build with for more than a decade, enabling a small team to continually ship improvements to customers from the same codebase, with the expanded capacity of many primary databases.
Enhancements in the last handful of versions like Multiple Databases support, disable_joins: true for associations have helped the team expand DB capacity, and still ship quickly to continue to deliver higher performance, and more reliable solutions to customers.
If these types of posts are interesting to you, please consider subscribing to my blog or buying my book.
If you’re an engineer interested in working on these types of challenges, please get in touch.
Thanks for reading!
Updates
2026-06-18 Chedli Bourguiba
:cursoroption for find_in_batches()- Replaced two instances of documentation with Edge Rails documentation
If you're interested in the PostgreSQL details for peak traffic on Christmas Day 2025, you may also enjoy From Christmas Outage to #1 App Store Ranking: An Aura Frames Postgres Scaling Retrospective .
