
- Original Context: Database and Table
- Partitioned Table Primary Keys
- The Reckoning
- Lock It Up
- Solution and Roll Out
- Placeholder Table and Hidden Table Modification
- The SQL
- Wrap Up
In Part 2 of this 2 part PostgreSQL 🐘 Table Partitioning series, we’ll focus on how we modified the Primary Key online for a large partitioned table. This is a disruptive operation so we had to use some tricks to pull this off.
If you haven’t already read Part 1 of this series, please first read PostgreSQL Table Partitioning — Growing the Practice — Part 1 of 2 which describes why and how this table was converted to a partitioned table.
The context there will help explain the circumstances we were operating from.
Original Context: Database and Table
- PostgreSQL 13
- Declarative partitioning with
RANGEtype - Table writes behavior is “Append Mostly”
- New writes at a rate of around 10-15 rows/second
- Pre-partitioned conversion: 2+ billion rows, 1.5 TB single table.
- Post-conversion: ~75+ partitions (old ones not yet detached), around 20 GB per partition where filled, around 24 partitions filled (monthly partitions), total of ~500 GB for all partitions and around 1 billion rows
- Primary Key constraint on child partitions on
idcolumn - No Primary Key constraint on parent
- Partition key column is
created_attimestamp
Partitioned Table Primary Keys
In the original partitioned table design, we set up a PRIMARY KEY constraint on each child partition, but none on the parent. This met the needs of the application.
Each child partition Primary Key was on the id column only. PostgreSQL allows the child table to have a Primary Key constraint with none defined on the parent, but not the other way around.
PostgreSQL prevents adding a Primary Key on the parent that conflicts with the child. 1 The Primary Keys need to match between the parent and child.
When we decided on the Primary Key and Unique Indexes structure for the table, the needs of the application and conventions of pgslice drove the decision. We didn’t have a need for a Primary Key on the parent table.
We found out later this was short sighted and in fact we did have a need for a parent table primary key.
So where did this need come from?
The Reckoning
The need for a parent table primary key came from outside the application. Our data warehouse detects row modifications and copies them to our data warehouse.
An engineer noticed an excessive amount of queries in the data warehouse since we’d partitioned the table.
The data warehouse was attempting to identify the new and changed rows, but it had become inefficient to do so without a Primary Key on the parent table. This inefficiency was spiking the costs on the data warehouse side, where we pay on a per query basis, making this a problem that needed to be fixed quickly!
After the team met, we decided the best course of action was to modify the Primary Key definition so that it existed on the parent. While the solution was clear, applying the change had immediate problems.
Lock It Up
In PostgreSQL table partitioning, the parent and child Primary Keys must match. On a partition parent table, the Primary Key must include the partition key column. This created an inconsistency with the child and this was a big problem because we couldn’t just easily add the primary key to the parent.
What we wanted to achieve was to have a composite Primary Key covering the id and created_at columns on the parent that would then be copied to all child partitions.
No problem, we’d just modify the Primary Keys for all tables, right? Unfortunately, this type of modification locks the table for writes, meaning we’d have an extended period of data loss if we missed writes. This was not a viable solution because the main big database was receiving writes at 10-15/second, and being locked for minutes wouldn’t be acceptable. We’d need another option.
We didn’t want to take planned downtime, we did want to modify the Primary Key definition, and we knew the modification would take a long time to run.
How could we solve this problem?
Solution and Roll Out
This same table would need to be modified on about 10 production databases, ranging in size from small to large. For the smaller databases we modified the child and parent Primary Keys and could tolerate the lock duration that blocked new writes since it was short.
We removed the existing Primary Key definition on all the child partitions and added the new Primary Key to the parent which propagates to the children.
However, for the big database we’d need a unique solution. The table would be locked for 10s of minutes with so many rows and so many partitions to modify.
We iterated through various approaches, and settled on a series of tricks to achieve on online modification.
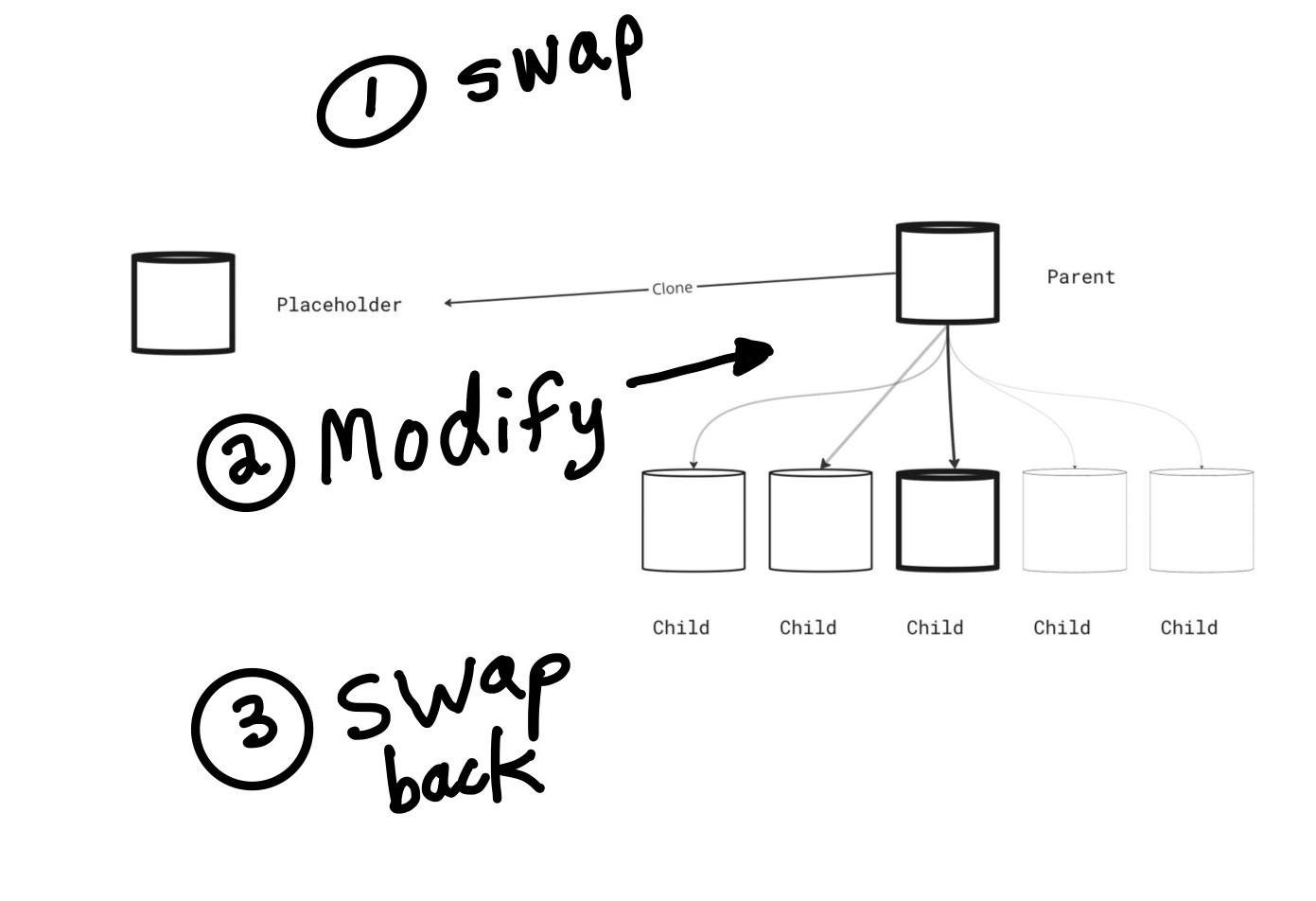
Placeholder Table and Hidden Table Modification
The strategy we used “hid” the lock period by performing the modification to a hidden table disconnected from concurrent transactions, behind the scenes.
To achieve this, we used a placeholder table that continued to receive writes and answer queries while the original table was being modified in the background.
For the placeholder table we cloned the original table. We swapped in the placeholder in a transaction with renames (ALTER TABLE ... RENAME TO) so that no writes would be lost.
The application would also read from this table as SELECT queries and a smaller amount of UPDATE queries.
We decided to duplicate some recent data into the placeholder so that it was available for the reads. The queries were for very recent data so if we duplicated some recent data it would be “good enough” to serve the queries while the placeholder table was in effect.
We’d discard the placeholder after it was no longer needed.
To make the duplication fast, we used the COPY command, and combined that with incremental copies right at the end.
The command below will dump the content of the month’s data into a file.
\copy tbl_202305 TO '/tmp/tbl_202305_dump.csv' DELIMITER ',';
We can then load the data from that file into the placeholder table.
\copy tbl_placeholder FROM '/tmp/tbl_202305_dump.csv' DELIMITER ',';
This load should be done right before the swap operation. To fill in what’s missed, we layered in the additional incremental inserts based on the last copied row id. Starting from the max(id) in the placeholder, we can copy in any new rows that were missed using the SQL below.
INSERT INTO tbl_202305 SELECT FROM tbl WHERE id > 123; -- the max(id) after loading from the file
We could run the statement above, and then even run it one last time inside of a transaction, to make sure that no rows were missed.
While the placeholder table was standing in, the ALTER TABLE and ADD PRIMARY KEY (id, created_at) modification could run. Applying the Primary Key constraint to the parent table and all children which ended up taking about 30 minutes (!!). Because it was done in the background it didn’t block any writes.
The diagram below shows the steps after the table was cloned and populated.
The sequence of steps are the first swap as step 1, modifications to the partitioned table as step 2, and then step 3 as a second fill and swap.
In the next section, we’ll share some of the SQL used to accomplish this.
The SQL
In the example below, tbl is the name of the table being modified. It has the columns id and created_at. The table was copied using INCLUDING ALL which includes extra objects like indexes but does not include data.
-- create an empty placeholder table
CREATE TABLE tbl_placeholder (LIKE tbl INCLUDING ALL);
-- swap tables around
BEGIN;
ALTER TABLE tbl RENAME TO tbl_offline;
ALTER TABLE tbl_placeholder RENAME TO tbl;
COMMIT;
-- Remove all the existing child-only primary key constraints
-- Repeat this for all children
ALTER TABLE tbl_202305 DROP CONSTRAINT tbl_202305_pkey;
-- Add the constraint now that the table is "offline"
-- This will propagate to all the children, which are also "offline"
ALTER TABLE tbl_offline ADD PRIMARY KEY (id, created_at);
-- Since we're also filling, perform a VACUUM on partitions
VACUUM ANALYZE tbl_202305;
-- Swap the tables a second time.
-- The "offline" table has been modified and is once again
-- ready to be put into duty
BEGIN;
ALTER TABLE tbl RENAME TO tbl_placeholder;
ALTER TABLE tbl_offline RENAME TO tbl;
COMMIT;
Wrap Up
In this post, we discussed a operational problem we encountered, where we determined we’d need to modify the PRIMARY KEY constraint on a large partitioned table.
Because this would lock the parent and children partitions, blocking concurrent transactions, we showed how to perform the modification using a placeholder table to handle writes and queries, and perform the modification offline by hiding the table.
This strategy meant we’d avoid disrupting any other transactions although the strategy was risky and required careful planning and execution.
Although this technique is not recommended for regular use, it was useful for an emergency scenario to work around normal table locking effects.
By writing up and rehearsing the steps in advance, pairing and mobbing on solutions on the team, the engineering team was able to perform this operation online without errors.
Once the primary key modification was complete, the excessive data warehouse queries stopped. The data warehouse could again efficiently determine new and modified rows using the new Primary Key configuration.
Thanks to Sriram Rathinavelu and Alesandro Norton for contributing to this project and for reviewing earlier versions of this post.
