
- Why Solid Queue?
- Adding Solid Queue to a Rails app
- Code to try
- Solid Queue for Postgres
- Using PostgreSQL for database backed jobs
- Benefits of job data in Postgres over Redis
- Advanced Postgres concepts worth considering for Solid Queue
- Drawbacks of background jobs in the database
- Features of Solid Queue
- What’s next
- More Solid Queue posts
Why Solid Queue?
Background jobs are commonly used in Ruby on Rails apps to perform any work possible outside of an HTTP request. A classic example is sending an email notification. Sending email from a background job places the latency there, outside of processing the request.
In the 2010s, Sidekiq became one of the most popular choices for processing background jobs. Sidekiq can be used as free, open source software, or commercially with the Pro version. Sidekiq uses Redis to persist job data.
Ruby on Rails added a middleware layer called Active Job back in Rails 4.2, that helped standardized background job using a consistent API. Background job systems then could become “backends” for Active Job. Starting from the upcoming release of Ruby on Rails 8, there’s a new official background job backend called “Solid Queue.” How does it work? What’s it like with PostgreSQL?
Let’s kick the tires!
Adding Solid Queue to a Rails app
To test it out, we’ll add Solid Queue to Rideshare.
To see background job data visually, we’ll add the Mission Control gem. We’ll generate a background job, process it, and take a look at what information about the job is visible.
Later in the post we’ll discuss some considerations for using Postgres for background jobs.
Code to try
# PR: https://github.com/andyatkinson/rideshare/pull/209
cd rideshare
bundle add solid_queue
bundle add mission_control-jobs
# config/environments/development.rb
config.active_job.queue_adapter = :solid_queue
Generate the migrations:
bin/rails solid_queue:install
The migrations are in a file called db/queue_schema.rb.
Running bin/rails db:migrate should pick these up and add the tables to your main application database. If you want to run a separate database for Solid Queue, which is not a bad idea, you’ll need additional configuration beyond what’s covered here.
Run:
bin/rails solid_queue:start
Let’s generate a “Hello World” type of job just to get something going through:
bin/rails g job SolidQueueHelloWorldJob
Open rails console and process and scheduled a Hello World job:
bin/rails console
SolidQueueHelloWorldJob.set(wait: 1.week).perform_later
Navigate to localhost:3000 and Mission Control, available at localhost:3000/jobs. View the scheduled job tab and verify the job is scheduled for a week out like below.
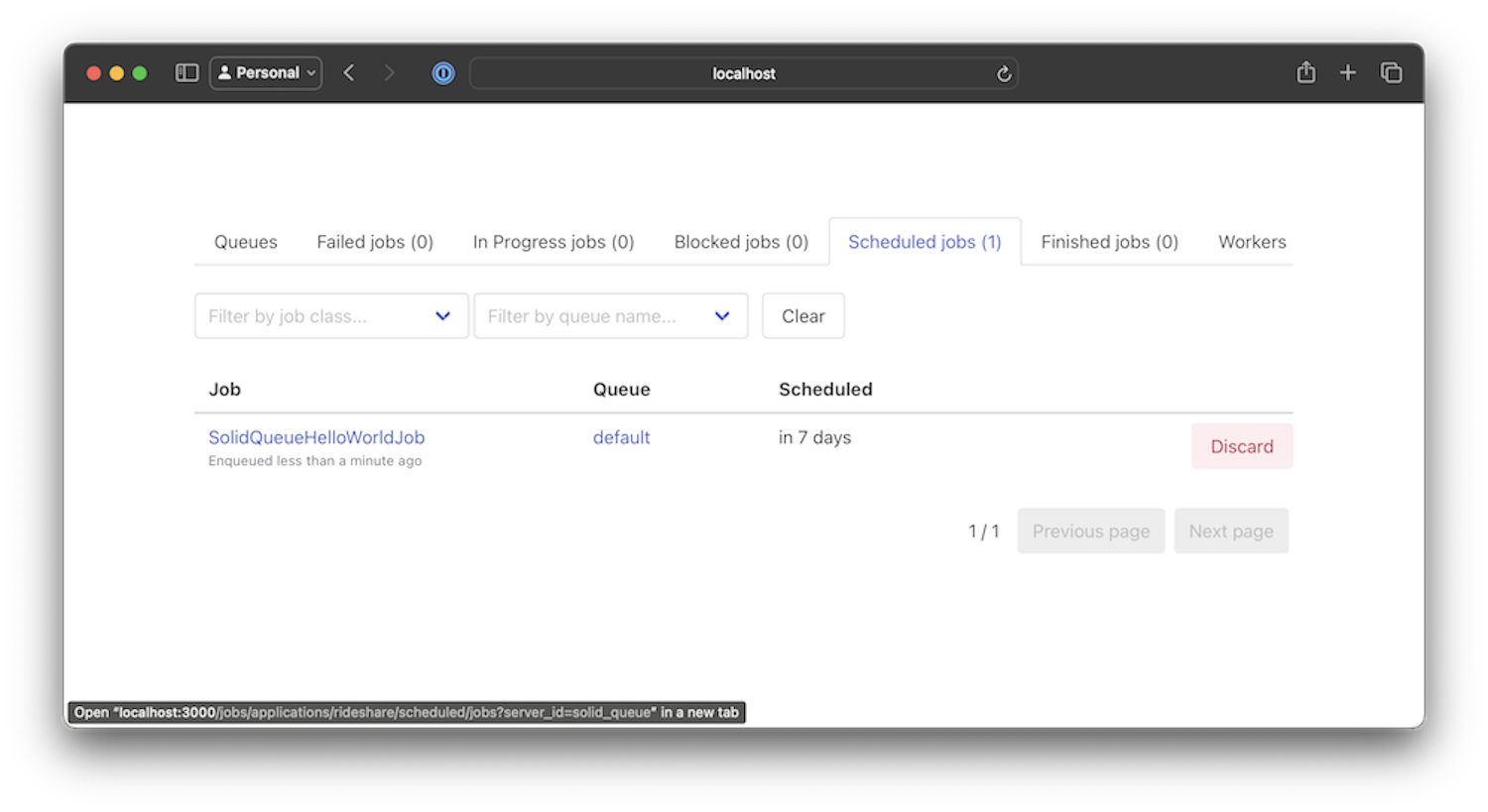 Mission Control view of Solid Queue Scheduled Jobs
Mission Control view of Solid Queue Scheduled Jobs
Let’s look at what Solid Queue is using in Postgres.
Solid Queue for Postgres
Solid Queue uses a clause when selecting jobs to update called FOR UPDATE SKIP LOCKED.
This clause is supported in Postgres. The first part FOR UPDATE is a locking statement that creates a row lock. The second part SKIP LOCKED means that rows that are already waiting to acquire a lock will be skipped when selected.
With the rows to be updated holding an exclusive lock, no concurrent updates can run while this lock is held and until it’s released.
This UPDATE has an implicit transaction which uses the Read Committed isolation level by default. This means only “committed” row updates are visible to the transaction at the time it started.
By using the SKIP LOCKED clause, UPDATE transactions currently holding a lock are skipped. This helps prevent concurrent UPDATE transactions from getting queued up waiting to acquire the same locks. Besides that it’s also a good idea to set a reasonably low lock_timeout1 which cancels statements that are waiting too long to acquire a lock.
This does mean that the client application skips rows to be processed, or could have statements canceled (when the timeout is set). In both of those cases the job processing should be retried using an automatic mechanism.
Is PostgreSQL a good choice to run background jobs on?
Using PostgreSQL for database backed jobs
Using PostgreSQL for background jobs is a good choice because you can leverage “transactional consistency” within the same instance that’s not possible when spanning heterogeneous data stores, or multiple instances. This means that transactions can be used to group actions together, like saving a record and enqueueing an email job, that should fail or succeed together, and not get split up.
PostgreSQL is also very reliable and capable of high scale operations. Its a great place to at least start running your background job work.
However, along with those benefits there are trade-offs. Update and Delete operations in PostgreSQL create new row versions, leaving old ones behind as part of the MVCC concurrency control design.
For Solid Queue tables with heavy updates and deletes, the Autovacuum resources for those tables in PostgreSQL should be increased. This means Autovacuum runs more frequently and for longer periods for those tables more so than others that don’t have those kinds of operational patterns.
For example, below we see updates and deletes for the table solid_queue_processes from the Rails log:
SolidQueue::Process Update (1.3ms) UPDATE "solid_queue_processes" SET "last_heartbeat_at" = '2024-09-06 03:42:29.963811' WHERE "solid_queue_processes"."id" = 3 /*application:Rideshare*/
DELETE FROM "solid_queue_processes" WHERE "solid_queue_processes"."id" = 1 /*application:Rideshare*/
The statement below reduces the vacuum scale factor threshold for solid_queue_processes from 20% to 1%, meaning when 1% of the row versions in the table are “dead”, a VACUUM operation is triggered. This is only one of several settings related to Autovacuum.
ALTER TABLE solid_queue_processes SET (autovacuum_vacuum_scale_factor = 0.01);
What are the benefits of background jobs in Postgres over Redis?
Benefits of job data in Postgres over Redis
- We can use a tool we’re familiar with:
bin/rails dbconsole(which is psql) to connect and view job data, as opposed to the Redis CLI - We can use SQL to query the job data tables
- We can leverage our schema knowledge if desired and change the schema for job data. Maybe there’s a constraint we want to add, or maybe we want to calculate some extra statistics about job data. Now we’re able to add additional tables that summarize data, and leverage SQL to do that.
- We can leverage our knowledge of backups, restores, and scaling database reads and writes we’ve learned from our application database experience, for our background jobs processing
Advanced Postgres concepts worth considering for Solid Queue
If write performance of job data is a concern, the Solid Queue Postgres tables could be made UNLOGGED.2 This disables the Write-Ahead Logging (WAL) that happens by default for table rows. In Postgres, unlogged tables are truncated on restart, which means they lose their data. Why do this then? The insert performance can be 10x better, and maybe the job data can be re-created in the unlikely event of a crash.
What other things might we consider in Postgres? When keeping job data forever, we may want to consider holding job data in a partitioned table. If the row counts grew into the hundreds of millions, performance will be better using a partitioned table that’s split up into smaller chunks behind the scenes. Solid Queue does not support partitioned tables as of this writing, so it may be a considerable undertaking to fork it and add support. I’m curious if there are any very large installations of Solid Queue processing hundreds of millions of jobs, and holding the job data forever.
Finally, while we’d lose transactional consistency described earlier, we may want to use Active Record Multiple Databases to relocate the Solid Queue tables to their own database. This second database would be where Active Job reads and writes to as background jobs are enqueued and processed. The benefit of a second PostgreSQL server instance is that it would have separate CPU, memory, and disk operations that could be scaled independently.
Drawbacks of background jobs in the database
- Fault isolation risk: By not segregating background job processing, it’s possible the load from background processing would harm the performance and reliability of the application database operations
- Data stores like Redis don’t have the MVCC design of Postgres, which means they may consume less disk space and server resources, achieving a higher processing rate
Features of Solid Queue
In a future post, we’ll dig more into the features. Here are the basics:
- Delayed jobs: see the example above where we’re delaying job processing by 1 week
- Concurrency controls: options like
max_concurrent_executionsthat can be set on individual jobs - Pausing queues: This can be useful for planned downtime events to temporarily stop processing
- Numeric priorities per job: Jobs will have different priorities in terms of their delivery time, with some needing near real-time, and others not
- Priorities by queue order: Solid Queue supports multiple prioritization schemes
- Bulk enqueuing: When working with bulk operations upstream, being able to bulk enqueue jobs saves processing time over enqueueing single items at at time
What’s next
Rails World 2024 is happening in a couple of weeks, and will include Solid Queue presentations by Rosa Gutierrez, a lead maintainer.
Rosa was interviewed in Episode #23 of the Rails Changelog and it’s worth a listen!
When Ruby on Rails 8 ships, more Rails developers will likely adopt Solid Queue. It will be interesting to see how adoption ticks up, and what sorts of issues emerge.
Thanks for reading!
