
- Setting up the data
- Digging Into “Rows Removed by Filter”
- Expectation versus reality
- What was happening?
- Performance details
- Additional information about “Rows removed by filter”
- Experiments with
OFFSET - Other Tidbits
- Takeaways
- Part Two
Recently, I was showing the PostgreSQL query planner output in a training session. We discussed the “Rows Removed by Filter” count as we prepared to add an index based on a high proportion of filtered rows.
The count was one less than the total row count, which made sense since the query had a LIMIT of 1, and was finding a unique value.
However, as I tried different WHERE clause values, the “Rows Removed by Filter” count started to confuse me. I realized I didn’t fully understand the behavior, and would need to dig in.
Along the way, I asked Michael Christofides (of PgMustard) for help. Michael was gracious to read this post, and even pair up and talk through the findings.
What did we find?
Setting up the data
We’re using the users table, rideshare schema, in the Rideshare database.
This table does not have a name_code column, so we’re adding that and populating it with the following SQL statements.
We’re disabling Autovacuum for the rideshare.users table to rule that out from interfering.
-- Disable Autovacuum so we have control over it
ALTER TABLE rideshare.users SET (autovacuum_enabled = false);
-- Add name_code column
ALTER TABLE rideshare.users
ADD COLUMN name_code VARCHAR (25)
DEFAULT NULL;
-- Populate name_code values
WITH u1 AS (
SELECT id,
CONCAT(SUBSTRING(first_name, 1, 1),
SUBSTRING(last_name, 1, 1),
FLOOR(RANDOM() * 10000 + 1)::INTEGER
) AS code
FROM users
)
UPDATE users u
SET name_code = u1.code
FROM u1
WHERE u.id = u1.id;
From this point forward, if you’re interested in following along, we’ll assume you’ve downloaded the Rideshare source code, created the database, the users table, and have applied the commands above.
This means when you run \d users you’ll have a name_code column and all 20,000+ rows will have a value populated.
Digging Into “Rows Removed by Filter”
Let’s discuss the table and query details, and other circumstances.
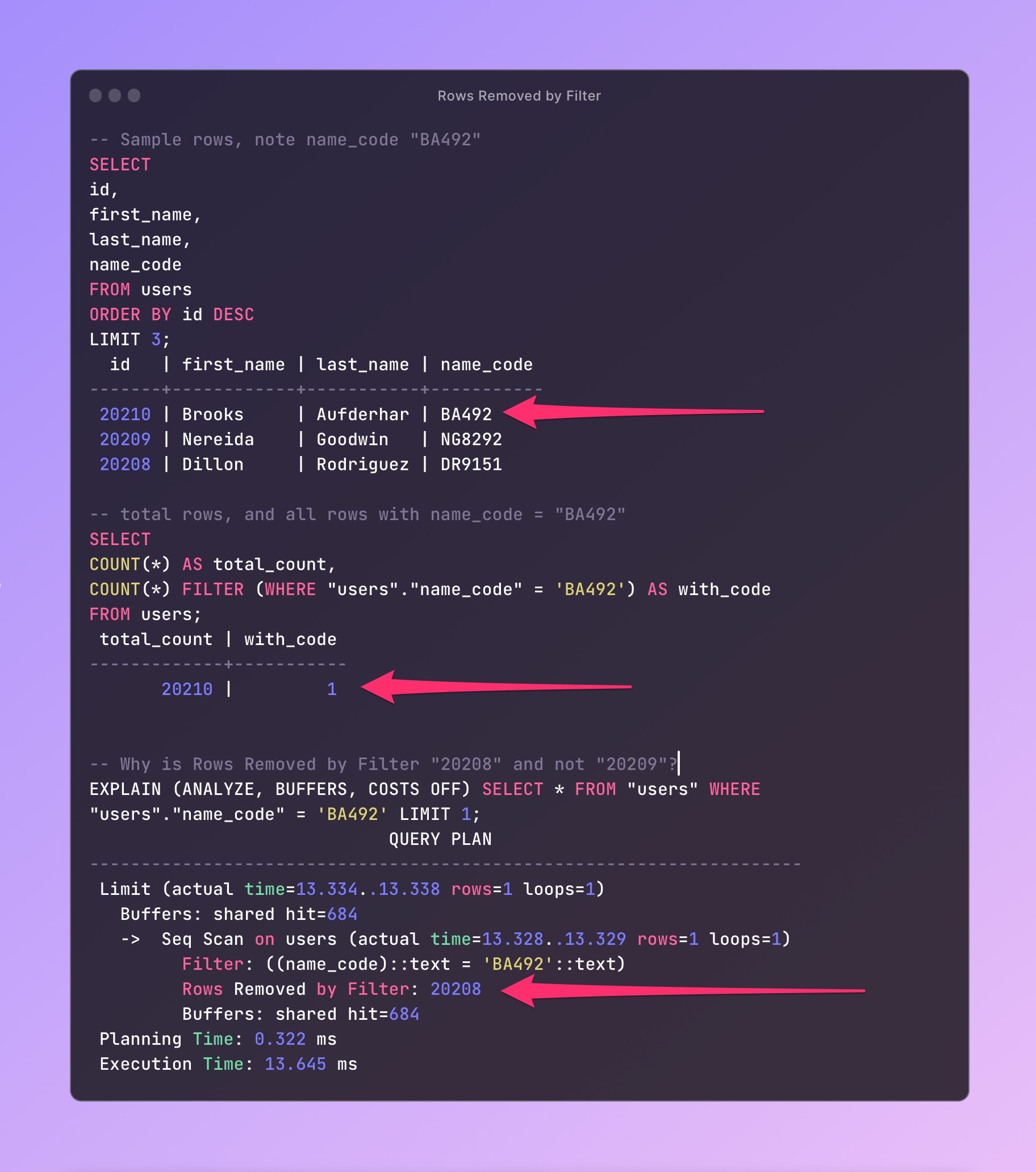
- We queried a “users” table with 20210 total rows. The table uses an integer sequence starting from 1.
- New rows are not being inserted. We’re working with a static set of rows in this post.
VACUUMhas not run for this table.- We used the same
WHEREclause in the query, changing only thename_codestring column, which holds a mostly-unique (but not guaranteed or enforced with a constraint) “code” value for each row. - We set a
LIMITof 1 on the queries, but noORDER BY, and noOFFSET. In practice, aLIMITwould often be accompanied by anORDER BY, but that wasn’t the case here. - A Sequential Scan was used to access the row data because there was no index. In a production system, an index on the
name_codecolumn would be a good idea. In this post we’re aiming to understand the behavior without that index. - All data was accessed from shared buffers, confirmed by adding
BUFFERStoEXPLAIN (ANALYZE)and seeingBuffers: shared hitin the execution plan.
 Analyzing “Rows Removed By Filter”
Analyzing “Rows Removed By Filter”
Expectation versus reality
Although I expected “Rows Removed by Filter” to be one less than the total row count, I learned there are a lot of reasons for why that wouldn’t be the case.
What was happening?
With the LIMIT 1 in the query, as soon as PostgreSQL found any match, there was an “early return.” There was no need to access additional rows in pages.
When supplying name_code values from earlier inserted rows, in earlier pages, we’d see smaller values for “Rows Removed by Filter.”
For name_code values “late” in the insertion order, many more rows were removed before finding a match.
We could confirm this in the planner output by observing greater numbers of buffers accessed.
Performance details
As stated, when prepending EXPLAIN (ANALYZE, BUFFERS) on the query, we saw fewer buffers accessed for these “early matches.”
With fewer buffers accessed, there was less latency, and lower execution times. However, performance wasn’t the goal of this exercise. If it was, it would make more sense to add an index covering the name_code column.
See: EXPLAIN (ANALYZE) needs BUFFERS to improve the Postgres query optimization process
Additional information about “Rows removed by filter”
One question I had was whether “Rows Removed by Filter” was an actual figure or an estimated figure.
The PgMustard Glossary explains it as:
This is a per-loop average, rounded to the nearest integer.
What does this mean? When more than one loop is used for the plan node (e.g. loops=2 or greater), then “Rows Removed by Filter” is an average value of the “Rows Removed by Filter” per-loop.
For example, if one loop removed 10 rows, and another removed 30 rows, we’d expect to see a value of 20 as the average of the two.
When there’s one loop (loops=1), the figure is the actual number of rows processed and removed.
Experiments with OFFSET
Michael pointed out how using OFFSET without ordering, would be correlated with “Rows Removed by Filter.”
To start, when we grabbed the name_code from the first row with the LIMIT 1, we didn’t see “Rows Removed by Filter” at all. In the default planner output format, when zero rows are filtered, the message is not displayed.
When we choose the second row (based on the default ordering), we see a single shared hit, and we see one row removed.
Next, we tried going to the “middle” of the 20 thousand rows, using an OFFSET of 10000, and supplying the name_code value to the query that first row at that offset, again without specifying an ordering for the query.
With that name_code, we see “Rows Removed by Filter: 10000”, which exactly matched the offset.
Other Tidbits
- The PostgreSQL EXPLAIN documentation describes how “Rows Removed by Filter” appears only when
ANALYZEis added toEXPLAIN. - “Rows Removed by Filter” applies for filter conditions like a
WHEREclause, but also for conditions on aJOINnode - “Rows Removed by Filter” appears when at least one row is scanned for evaluation, or a “potential join pair” (for join nodes) when rows were discarded by the filter condition.
- Michael noted that using
ORDER BY, which is commonly used withLIMIT, can produce more predictable planner results. See this thread: https://twitter.com/Xof/status/1413542818673577987
Takeaways
- Without an explicit ordering (
ORDER BY), and when using aLIMIT, the results of “Rows Removed by Filter” may be surprising. - When
LIMIT 1is used, PostgreSQL finds the first match and returns. The default ordering is likely the insertion order of the rows. - When analyzing “Rows Removed by Filter” figures, check whether the plan node had more than one loop. In that case, the rows are an average of all loops, rounded to the nearest integer.
- For performance work, a high proportion of rows filtered out indicates an optimization opportunity. Adding an index may greatly reduce the filtering of so many rows, reducing storage access, and speeding up your query.
Part Two
Check out the second part of this series, where we continue analyzing Rows Removed by Filter, inspecting disk pages and the buffer cache.
Check out part two here: ‘Rows Removed By Filter’, Inspecting Page, Buffer Cache — Part Two.
Thanks for reading!
